

Азбука медицинской статистики. Глава I. C чего начинается статистический анализ?
Вся статистика — это изучение того, как один параметр влияет на другой, как они соизменяются

Досье КС
Константин Кравчик
Математик-аналитик. Специалист в области статистических исследований в медицине и гуманитарных науках
Москва
На сегодняшний день существует огромное количество статей по клиническим исследованиям. Клиницист, стремящийся к глубоким знаниям, наверняка знает про базы медицинских статей, например, pubmed, eMedicine World Medical Library, National Library of Medicine — National Institutes of Health и так далее. Статьи в этих базах написаны строгим научным языком, с указанием методов статистического анализа. Читатель, не искушенный в статистике, встречается с большим количеством неясных ему терминов, например: «анализ мощности» и «расчет количества выборки», «критерии сравнения средних», «корреляции», «отношения шансов», «пропорциональные риски» и так далее. Если читатель не понимает, что это такое, то он или закроет статью, или не сможет оценить, адекватно ли автор применил статистические методы для анализа эмпирических данных и можно ли доверять полученным выводам. Итак, начнем с азов.
Медиана, мода, среднее, разброс
Рассмотрим пример: исследование охватило 200 человек с ожирением. Вес участников исследования колебался от 105 до 203 кг. Это разброс значений, или дисперсия. Средний вес составил 120 кг — это среднее значение веса в выборке. К примеру, 30 из 200 человек имели вес 115 кг. Остальные весили по‑разному, поэтому 115 — оказалось самым «популярным» значением веса в выборке, то есть модой веса.
Даже на базе этих данных мы можем составить представление о том, как выражен изучаемый признак: большинство участников исследования весило ближе к 100 кг, и только немногие весили около 200. Кроме определения «чистого» веса можно, например, ранжировать (разделить) пациентов по индексу массы тела — ИМТ. Например, 1 — ожирение первой степени (ИМТ 30–35), 2 — ожирение второй степени (ИМТ 35–40), 3 — ожирение третьей степени (ИМТ более 40). И тут мы плавно подходим к понятию шкал переменных.
Какие бывают шкалы
Для справки
Медиана — значение, которое делит ряд чисел (распределение) ровно пополам, так что одна половина больше этого значения, а вторая меньше. Например, семерка для ряда чисел 2, 3, 3, 4, 7, 5, 6, 9, 9. Если в выборке чётное число элементов, медиану чаще всего высчитывают как полусумму двух соседних значений. Например, медиану набора {1, 3, 5, 7} принимают равной 4.
Мода — значение во множестве наблюдений, которое встречается наиболее часто. Мода достаточно редко встречается в медицинских исследованиях, однако является базовым понятием статистики.
Общепринято использовать классификацию шкал измерения, предложенную американским психологом Стенли Стивенсоном еще в 1946 году.
1. Номинативная (категориальная) шкала
Это шкала классификации каких‑то категорий. Например, пациентов можно разделить по полу, по уровню холестерина в крови (высокий, низкий, средний), степеням ожирения, как в приведенном примере, и т. п.
С этой шкалой нельзя производить никаких математических действий (сложение, деление, вычитание, умножение). Номинативные переменные часто называют группирующими, они нужны, для того чтобы разбить выборку на осмысленные категории.
2. Порядковая (ранговая) шкала
Показывает степень выраженности признака, когда приписывается ранг от «очень слабо выражен» до «очень сильно выражен». Частный случай ранговой шкалы — это шкала суммарных оценок Лайкерта, которая часто используется в опросниках.
Например, в Болевом опроснике Мак-Гилла есть вопрос:
Как Вы оцениваете свою боль? Ответы: слабая, умеренная, сильная, сильнейшая, невыносимая.
Если пациент Петров описал свою степень боли как сильную, а пациент Иванов как невыносимую, мы понимаем, что Иванову скорее всего больнее, чем Петрову, условно говоря, на 2 пункта. Однако ранги — это неметрическая шкала, которая не несет количественной информации.
Еще к специфичным ранговым шкалам можно отнести шкалу Жана Стэпела. Это 10‑балльная шкала без нулевой точки, которая позволяет оценить, насколько верно или неверно каждое утверждение описывает вопрос. Например, вопрос к пациенту: «Вы считаете, что терапия этим лекарством Вам помогла?».
Да, терапия эффективна:
– 5, – 4, – 3, – 2, – 1, 1, 2, 3, 4, 5
Нет, терапия неэффективна:
– 5, – 4, – 3, – 2, – 1, 1, 2, 3, 4, 5.
Чем выше число, тем больше согласие с утверждением.
С помощью ранговых шкал мы можем, во-первых, высчитать меру разброса, моду и медиану, а во‑вторых, сравнивать признак в нескольких выборках, например, у мужчин и женщин, в группе вмешательства и группе плацебо. Данные методы будут рассмотрены в следующих выпусках журнала.
3. Метрическая шкала
К ней относятся непрерывная шкала и шкала отношений (абсолютная шкала).
В непрерывной шкале значения лежат в диапазоне от минус бесконечности до плюс бесконечности. Классический пример — это температура по Цельсию. В этой шкале 0 («ноль») не означает отсутствие признака, например, температура воды в 0 ºС не означает, что у воды нет температуры. В этой шкале мы можем сказать, насколько больше или меньше выражен признак.
Шкала отношений такая же, как и непрерывная, но в ее случае 0 означает отсутствие признака. К примерам такой шкалы относятся рост, вес, возраст, т. к. не может быть роста минус 1,5 метра или веса в минус 50 килограмм.
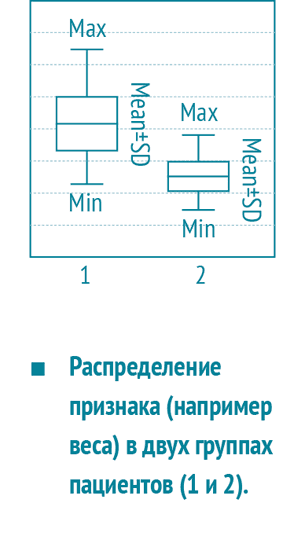
М±SD
Часто в научных статьях мы видим такие понятия, как дисперсия, стандартное отклонение, размах. Это одни из самых важных понятий в статистике, и обозначают они меру разброса значений изучаемого признака.

Разброс — показатель того, насколько значения признака отклоняются от его среднего значения.
К каждой шкале применима своя мера разброса. Например, уровень гемоглобина — это метрическая шкала. Для такой шкалы характерная мера разброса — это дисперсия, показатель разнородности значений признака. Дисперсия (D) измеряется в квадратных единицах признака, в случае гемоглобина — (г/л)2, поэтому для удобства изучения можно извлечь корень из дисперсии √D и получить стандартное отклонение (standart diviation — SD), которое обозначают буквой σ (сигма). Стандартное отклонение характеризует разброс в обе стороны от среднего значения.
Для шкалы Лайкерта можно использовать стандартное отклонение.
Тем не менее иногда в статьях и диссертациях можно заметить, что размах используется совместно со стандартным отклонением для метрических переменных.
Среднее обозначают буквой µ (Мю) или М. Таким образом, если средний уровень гемоглобина µ=96, а стандартное отклонение σ=20, то диапазон значений лежит в пределах µ±σ (М±SD), или, в нашем случае, 96±20, то есть диапазон от 76 до 116. Важно помнить, что в этом диапазоне будет лежать 68 % значений признака в случае нормального распределения, 95 % значений лежат в пределах двух сигм и 99 % лежат в пределах трех сигм, но об этом в следующем номере.

25740 просмотров
Поделиться ссылкой с друзьями ВКонтакте Одноклассники
Нашли ошибку? Выделите текст и нажмите Ctrl+Enter.
зарегистрированным пользователям